
Loss Functions for Computer Vision Models
Machine learning algorithms are designed so that they can “learn” from their mistakes and “update” themselves using the training data we provide them. But how do they quantify these mistakes? This is done via the usage of “loss functions” that help an algorithm get a sense of how erroneous its predictions are when compared to the ground truth. Choosing an appropriate loss function is important as it affects the ability of the algorithm to produce optimum results as fast as possible.
Basic Definitions
L2 LOSS
- This is the most basic loss available and is also called as the Euclidean loss. This relies on the Euclidean distance between two vectors — the prediction and the ground truth.
- This is very sensitive to outliers as the error is squared.

CROSS-ENTROPY LOSS
- Cross Entropy loss is a more advanced loss function that uses the natural logarithm (loge). This helps in speeding up the training for neural networks in comparison to the quadratic loss.
- The formula for cross entropy (multi-class error) is as follows. It may also be called as categorical cross entropy. Here c=class_id and o=observation_id, p=probability

- The formula for cross entropy (binary class) is as follows. It may also be called as log loss. Here y = [0,1] and yˆ ε (0,1)

- For more information refer fast.ai wiki or this github gist.
SIGMOID FUNCTION
- The cross entropy function requires probabilities to be input for every scalar output of an algorithm. But since that may not always be the case, we can use the sigmoid function (a non-linear function). Its formula (which is a special case of the logistic function) is as follows.

SOFTMAX FUNCTION
- We can use the softmax function for the same reason as stated above. This is also referred to as a normalized exponential function (this is a generalization of logistic function over multiple inputs). It “squashes” a K-dimensional vector(z) to a K-dimensional vector(σ(z)) in the range (0, 1) that add up to 1. One can also read up the definition here. The equation is as follows

Examples of Loss Functions in Popular Semantic Segmentation Models
Semantic Segmentation — PSPNet
- Quote from “Pyramid Scene Parsing Network”, Zhao et.al
Apart from the main branch using softmax loss to train the final classifier, another classifier is applied after the fourth stage, i.e., the res4b22 residue block.
- Here the softmax loss refers to softmax activation function followed by the cross-entropy loss function.
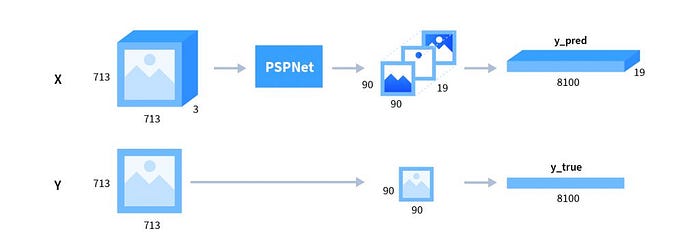
- Loss Calculation (code)
- The above code snippet defines loss on the masks for PSPNet. It is Split into three main section
- Step1: Reshaping the inputs
- Step2: Gathering the indices of interest
- Step3: Computing loss (Softmax Cross Entropy)
- Inference (code)
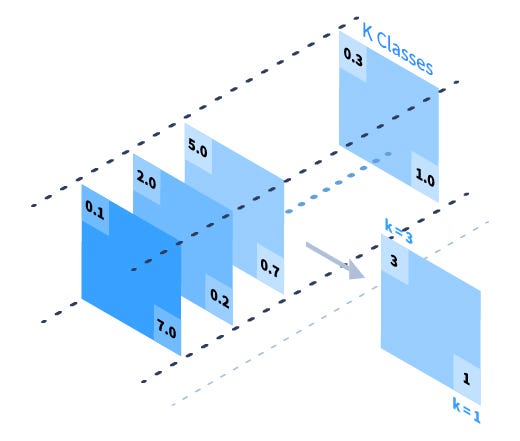
raw_output_up = tf.argmax(raw_output_up, dimension=3)raw_output_up = tf.argmax(raw_output_up, dimension=3)- Here we calculate the class_id for each pixel by finding the mask with the max value across dimension=3 (depth)
Instance Semantic Segmentation — MaskRCNN
- Quote from “Mask R-CNN”, He et.al
The mask branch has a Km 2 — dimensional output for each RoI, which encodes K binary masks of resolution m × m, one for each of the K classes. To this we apply a per-pixel sigmoid, and define L mask as the average binary cross-entropy loss. For an RoI associated with ground-truth class k, L mask is only defined on the k-th mask (other mask outputs do not contribute to the loss).
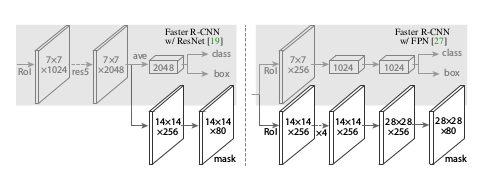
- Network Architecture
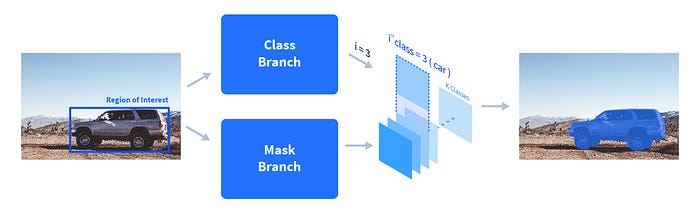
- As can be seen below, Mask-R-CNN splits into three branches — classes, bounding box, and mask. Let’s focus on the mask branch since that’s the one used to create masks for various objects of interest.
- Loss Calculation (code)
- The above code snippet defines loss on the masks for MaskRCNN. It is Split into three main section
- Step1: Reshaping the inputs
- Step2: Gathering the indices of interest
- Step3: Computing loss (Binary CrossEntropy Loss)
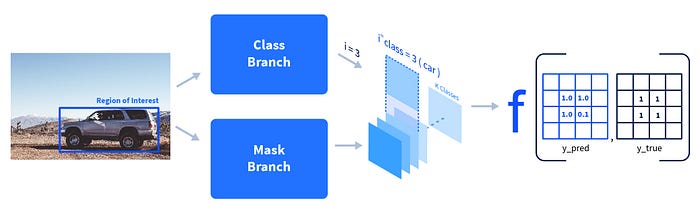
- Inference
- The class branch predicts the class id of a region of interest and that mask is accordingly picked out from the prediction
Conclusion
Here we learned about some basic loss functions and how their complex variants are used in state-of-the-art networks. Specifically, we looked at how Cross Entropy in used in two popular semantic segmentation frameworks — MASK-RCNN and PSPNet. The associated code snippets should give a better idea of the implementation complexities.
Recently, other loss functions such as the DICE loss are used in various medical image segmentation tasks as well.
Go ahead and play around with the repositories in the links above!
Originally published on Playment Blog
